Bazy danych – jak obsługiwać?
W tym artykule chciałbym przedstawić jakie istnieją możliwości obsługi baz danych podczas budowy naszej aplikacji. Poruszę tematy związane z bezpośrednią implementacją logiki po stronie bazy danych oraz z wykorzystaniem ORM (object-relational mapper), postaram się opisać ich wady i zalety oraz przytoczę trochę historii. Pozwoli to dać szerszy kontekst przy wyborze rozwiązania.
Do kogo kieruję ten artykuł?
Przede wszystkim do osób projektujących swoje aplikacje, które obecnie (prawie zawsze) zawierają relacyjną bazę danych (jedną lub kilka). Nie będę mówić o bazach innych niż relacyjne lecz postaram się do nich odwołać. Problem jaki identyfikuję to zjawisko, w którym programiści kopiują przykłady z ogólnodostępnych poradników i tutoriali gdzie zastosowano do obsług bazy danych z poziomu aplikacji mechanizm mapowania relacyjno-obiektowego ORM (Object Relational Mapping) lub innych podobnych rozwiązań, a które w późniejszej fazie rozwoju aplikacji mogą powodować bardzo dużo problemów. Jest to wynikiem myślenia: pokazali jak to zrobić, na razieb> działa i na razie nie ma problemów (oczywiście chciałbym przestrzegać przed rozwiązaniem problemów wydajnościowych zanim się one pojawią i przed tz. „przedwczesną optymalizacją”).
Jakie są tego konsekwencje?
Uważam że baza danych często traktowana jest jako mało istotny element systemu (bo przecież baza danych to tylko pudełko na dane – tak twierdzi wielu programistów!), a to brak świadomego jej obsługiwania prowadzi często do problemów wydajnościowych.
Co jest celem tego artykułu?
Chciałbym uświadomić istnienie problemu jakim jest obsługa bazy danych przez tworzoną aplikację lub system. Po obejrzeniu kilku przykładów wykonanych aplikacji oraz systemów, z którymi były problemy wynikające z braku świadomości istnienia zależności pomiędzy bazą danych a czasem wykonania niektórych funkcjonalności, które korzystały z baz danych. Czytając kod źródłowy i poznając obsługę bazy danych z poziomu aplikacji wykorzystującej ORM można zauważyć, że wiele z tych przypadków można by było w prosty sposób zastąpić SQL były robione na około z użyciem ORM i bardzo dużej ilości zapytań (często w pętli). Ten artykuł ma na celu przybliżyć jakie problemy występują oraz w jaki sposób podjąć świadomą decyzję. Niezależnie od tego co zostanie wybrane nie ma jednego dobrego sposobu na obsługę bazy danych. Ważne aby poznać wady i zalety poszczególnych rozwiązań.
Co jest naszym celem podczas wyboru sposobu obsługi bazy danych?
To zależy. W jednym przypadku może być prostota rozwiązania, w kolejnych łatwa skalowalność, wprowadzanie zmian lub łatwość utrzymania. Podczas wyboru powinniśmy dostosowywać rozwiązanie do problemu, a nie problem do rozwiązania.
Jak można to uzyskać?
Przede wszystkim zaplanować przed przystąpieniem do pracy. Niezbędna jest analiza i ustalenie priorytetów. Inaczej będziemy robić bazę danych dla projektu który ma z góry ustalone wymagania i raczej rzadko się zmienia a inaczej dla prototypu gdzie szybko chcemy uzyskać efekt. Niezależnie od tego jaka decyzja zostanie podjęta należy ją podejmować w oparciu o fakty i kierować się uzasadnieniem dlaczego dane rozwiązanie zostało wybrane, a też dlaczego inne zostały odrzucone.
Porównanie modeli pytania bazy danych
Pomiędzy bazą danych a aplikacją może być zastosowana dodatkowa warstwa w postaci ORM (Object Relactional Mapper – mapper obiektowo relacyjny). Oczywiście obecność mappera nie wyklucza pytania bazy danych bezpośrednio.
Można zatem wyróżnić dwa sposoby pytania bazy danych:- bezpośrednie pytanie poprzez zapytania SQL
- pośrednie za pomocą ORM
Jak pytać bazę danych? Trochę filozofii
Baza danych zazwyczaj posiada potężny silnik obsługiwany poprzez język SQL. Jego wykorzystanie pozwala ograniczyć przesyłanie danych przez sieć oraz przyspieszyć zapytania. Więc do czego właściwie dążymy?
Z obsługą (pytaniem) baz danych jest jak z jedzeniem i zostało to opisane w Staropolskim piśmie:Panny, na to się trzymajcie, Małe kęsy przed się krajcie, Ukrawaj często, a mało, A jedz, byleć się jedno chciało.
WIERSZ SŁOTY O CHLEBOWYM STOLE, Przecław Słota 1415
Przytoczony tutaj cytat jest analogią do baz danych. Jeżeli zamiast Panny podstawimy bazę danych, a zamiast jedzenia zapytania których celem jest zadowolenie nie rycerza, a użytkownika mamy analogię w jaki sposób powinniśmy obsługiwać bazę danych. Przesyłać jak najmniej ale często (małymi porcjami). Wtedy użytkownik będzie zadowolony.
Jak to robili kiedyś i dlaczego powstały ORM?
ORM nie są rzeczą które towarzyszyły aplikacją od zawsze. Pierwsze ORM powstały w okolicach 1994 roku. Bazy relacyjne znane są od 1970 roku gdy to Edward Frank „Ted” Codd pracujący w firmie IBM je opracował. Bazy danych były używane przez wiele lat bez ORM i działały.
Więc dlaczego powstały ORM?
Przede wszystkim aby oszczędzać czas i pieniądze. Moc obliczeniowa komputerów rosła na tyle szybko że można było sobie pozwolić na dodatkową warstwę abstrakcji. Systemy informatyczne były już na tyle duże (jak na tamte czasy) że zaczęto potrzebować takich rozwiązań. Późniejsze lata to bardzo duży rozwój informatyki i wymusiły takie podejście. Dlaczego? Było ono tańsze.
Dlaczego są one tańsze?
Załóżmy że do zrobienia jest aplikacja typu CRUD (create, read, update, delete) – aplikacja będąca „nakładką” na bazę danych wykonująca operację dodawania, odczytu, aktualizacji oraz usuwania danych. Do obsługi takich aplikacji użyjemy generatora, który na podstawie modelu danych (w bazie danych) wygeneruje klasy. Chcąc dodać prostą logikę biznesową (np. koszyk klienta nie może zawierać więcej jak 100 produktów) dużo szybciej uzyskamy to po stronie aplikacji. Obsługa takiej logiki po stronie bazy danych wymagałaby np. napisania funkcji dodawania produktu do koszyka oraz zwracania błędu jeżeli klienta posiada zbyt dużą liczbę produktów w koszyku. W przypadku niezmieniającej się logiki biznesowej można takie rozwiązanie przyjąć, lecz gdy wymagania się zmieniają bardzo trudno utrzymać taki model z powodu jego nadmiernego skomplikowania. Logika po stronie bazy danych jest raczej rzadko spotykana, lecz jest to najbardziej stabilny sposób przechowywania logiki. Silnik bazy danych jest wymieniany na inny najrzadziej z wszystkich komponentów systemu. Ta sama logika po stronie bazy danych będzie dostępna (bez warstwy aplikacji „backendu”) po stronie aplikacji desktopowej, webowej oraz mobilnej.
Historia ORM: https://antoniogoncalves.org/2008/09/27/a-brief-history-of-object-relational-mapping/Dlaczego należy ograniczać ilość danych przesyłanych pomiędzy aplikacją a bazą danych?
Podczas gdy wywołujemy zapytanie, które zwraca dużą ilość danych konieczne jest ich podzielenie na mniejsze części (np. pakiety) oraz wysłanie. Takie przesyłanie to dodatkowy czas oraz zapchanie łącza. Jeżeli zapytań nie jest dużo nie jest to problem, jednak w momencie gdy ich liczba zwiększy się do poziomu gdy zapytania muszą czekać na wywołanie pojawiają się problemy. Wykonując logikę zapytania po stronie aplikacji zdarza się, że przesyłamy wszystkie dane potrzebne do wykonania zapytania. Efektem tego jest bardzo wolne przetwarzanie zapytań, co może być z punktu widzenia biznesowego nieakceptowane. Najszybszym sposobem na pytanie bazy danych jest wykonywanie zapytań po stronie serwera bez pośrednictwa ORM i przesyłanie tylko wyniku. Dzięki temu silnik bazy danych sam zoptymalizuje plan wykonania (a jeżeli jest to widok sam pobierze już istniejący) i prześle tylko niezbędną ilość danych. Pobieranie dużej ilości danych i wykonywanie na nich operacji po stronie aplikacji jest bardzo kosztowne pod względem wydajności naszego serwera. Oczywiście ORMy oferują optymalizację zapytań jednak często zdarza się że programiści chcąc wywołać prostą funkcję przesyłają masę danych oraz wykonują na nich bardzo wiele zapytań.
Model tani vs model drogi
Logika po stronie bazy danych jest bardzo droga w napisaniu oraz utrzymaniu w porównaniu do ORM. Baza danych jest jednak bardzo stałym elementem systemu i zmienia się bardzo rzadko. Jeżeli logika po stronie bazy danych zostanie poprawnie zaimplementowana można bardzo dobrze obsługiwać nasz system, ponieważ nawet w przypadku gdy będzie rósł (pod względem ilości danych) można optymalizować zapytania. Takich możliwości nie daje na ORM (przynajmniej nie w takim stopniu), lecz jego niewątpliwą zaletą jest szybkość wprowadzania zmian.
Gdzie zauważymy to najmocniej?
Wszędzie tam gdzie ORM nie poradzi sobie z optymalizacją. Przykładem jest implementacja drzewa po stronie bazy danych. Realizowane jest to za pomocą tabeli z samozłączeniem. Zapytanie o ścieżkę do korzenia wymagałoby tylu zapytań jak głębokie jest drzewo. W przypadku rekurencyjnego zapytania SQL po stronie bazy danych optymalizowany jest plan wykonania i zwraca tylko szukaną wartość.
HierarchyID oraz inne próby implementacji modelu grafowego w bazach relacyjnych
Potrzeba obsługi grafowych struktur danych jest na tyle duża, że kilku czołowych producentów silników baz danych wprowadziło typy danych umożliwiające przedstawienie grafu po stronie bazy relacyjnej. Rozwiązania te nie przyjęły się i nadal praktykowana jest tabela z samozłączeniem oraz grafowe bazy danych np. GraphQL. Powodem takich działań jest konieczność integracji z innym produktem oraz brak typu danych pozwalającego na przechowywanie struktur grafowych w standardzie SQL.
Kiedy może być konieczna wymiana silnika bazy danych?
Zabezpieczenie się na konieczność wymiany silnika bazy danych na inny wydaje się bardzo mocno nie uzasadnione. Dodanie warstwy abstrakcji oraz słabe zależności (lub ich brak) z konkretnym silnikiem bazy danych znacząco zredukują koszt ewentualnej migracji oraz osłabia zależność pomiędzy aplikacją, a silnikiem bazy danych.
Przykłady, kiedy wymiana silnika bazy danych była konieczna:- migracja całego środowiska do chmury obliczeniowej (problemy licencyjne u niektórych dostawców lub brak możliwości ich uruchomienia)
- zmiana architektury, na której uruchamiany jest system (zmiana architektury procesorów)
- zmiany w sposobie licencjonowania bazy danych (np. migracja z MySQL do MariaDB).
- konieczność fuzji dwóch podobnych systemów w przypadku połączenia się firm
- potrzeba funckjonalności dostępnych tylko w niektórych silnikach bazy danych (np. PostGIS do PostgreSQL).
- narzędzia do procesu ETL nie są w pełni kompatybilne z silnikiem bazy danych
- polityka firmy wymuszająca ujednolicenie systemu baz danych w celu łatwiejszego utrzymania
- potrzeba skalowalności aplikacji i jednoczesnych połączeń do bazy danych
Zmieniające się wymagania
Do lat 90. systemy informatyczne były stosunkowo małe a przedsiębiorstwa używały ich w bardzo ograniczonym stopniu. Sprzęt był drogi i nie dający zbyt wielkich możliwości. Początek lat 90. to obniżenie cen sprzętu oraz możliwości wykorzystania ich na globalną skalę. Tworząc systemy w oparciu o logikę po stronie bazy danych nie możemy (lub jest to bardzo trudne) dostatecznie szybko dostarczać aplikacji dostosowując się do zmieniających się wymagań.
Czy przyjęło się od razu?
ORM jak każda technologia powstała i zanim ludzi zrozumieli kiedy należy jej używać minęło trochę czasu.
Można to zawrzeć na wykresie:
Gdzie tak na prawdę leży problem logiki w bazie danych?
W naciskach na zmiany w aplikacjach wywieranych przez biznes na programistów. Przekłada się to na brak czasu zgłębiania jak działają zapytania SQL oraz pogłębiania wiedzy w tym temacie. Bardzo rzadko można spotkać się z programistami umiejącymi programować bazę danych. Większość z nich ograniczała się do widoków, a pisanie funkcji lub wyzwalaczy było dla nich katorgą. Nie ma co się temu dziwić, gdyż pisanie takich rzeczy nie jst proste. Pisanie po stronie bazy danych wymaga zmiany sposobu myślenia z struktur, klas, dziedziczenia na zbiory i relacje, co nie jest proste.
Jak wygląda model obsługi bazy danych w każdym z przypadków?
Przedstawiłem to na poniższym obrazu: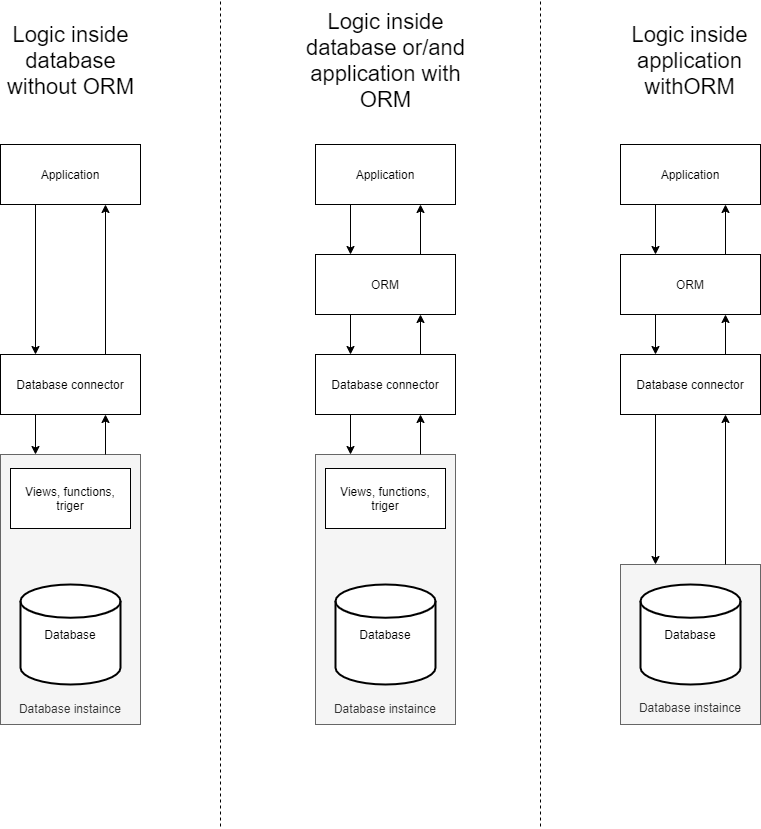
- Logic inside database without ORM – zapisujemy całą logikę aplikacji po stronie bazy danych nie korzystając z ORM. Łączy się do bazy danych za pomocą zapytań SQL generowanych w kodzie.
- Logic inside database or/and application with ORM – zapisujemy logikę w aplikacji i/lub bazie danych (i dotyczy modelu hybrydowego gdzie część logiki jest po stronie aplikacji a część po stronie bazy danych) łączymy się do bazy danych za pomocą ORM.
- Login inside application with ORM – całą logikę zamykamy po stronie aplikacji a do bazy danych odwołujemy się jak do „pudełka na dane”.
Wady i zalety każdego z rozwiązań
Które rozwiązanie jest najlepsze? To zależy. Wybór zależeć będzie od wielu czynników m.in. czasu jaki chcemy poświęcić na development oraz naszej wiedzy. Stworzenie dobrej logiki po stronie bazy danych nie jest proste, a jak już to zrobimy jej utrzymanie będzie kłopotliwe. Stosowanie samego ORM przy małych projektach da nam szybko efekt, lecz gdy baza danych będzie się powiększać mogą wystąpić problemy z wydajnością. Poniżej przedstawiono tabelę modeli, która może pomóc podjąć decyzję. Przed wybraniem modelu dobrze jest przede wszystkim wypisać listę priorytetów i posortować je od najbardziej istotnego.
| logic inside database | |||||
| hard | hard | easy | |||
| hard | hard | easy | |||
| performance | high | high | low | ||
Modele hybrydowe
Każdy z powyższych modeli możemy stosować obok siebie. Jeżeli projektowana aplikacja posiada bardzo dużo odczytów może lepiej zastosować zapytania bezpośrednie (jeżeli są możliwe) do bazy danych z pominięciem mappera obiektowo-relacyjnego, a ORM zastosować tam gdzie są skomplikowane zapytania i bardzo dużo skomplikowanych zależności.
Przedwczesna optymalizacji
Projektując obsługę bazy danych można wpaść w pułapkę przedwczesnej optymalizacji. Polega ona na rozwiązywaniu problemów które jeszcze się nie pojawiły i nie wiadomo czy się pojawią. Temat jest o tyle trudny, że bardzo ciężko oszacować czy jakieś zapytanie będzie szybkie/wolne i jak dużo zasobów będzie potrzebne do jego wykonania. Jedyne na podstawie czego możemy szacować takie rzeczy to doświadczenie z poprzednich projektów.
BaaS – Backend as a service
Przy obecnie tworzonych aplikacjach istnieją usługi zwane backed as a service. Są to zestawy gotowych funkcji, które pozwalają nam operować na danych z poziomu aplikacji (biblioteka do obsługi). Obecnie najpopularniejsze na rynku są dwie usługi tego typu: Firebase (Google) oraz AWS Amplify (Amazon). Mają bardzo wiele zalet i można za ich pomocą zbudować całe aplikacje. Szczególnie popularne są w przypadku tworzenia aplikacji mobilnych.
Zalety:- bardzo niski próg wejścia (w zasadzie nie musimy znać baz danych)
- bardzo szybko uzyskujemy efekt
- nie martwimy się o serwer
- nie martwimy się o skalowalność
- płacimy tylko za to ile wykorzystamy
- Vendor-lock-in – usługi nie są za sobą kompatybilne i nie możemy przenieść bazy z Google do Amazon lub z Amazona do Google bez jej przebudowy
- Wykorzystane mechanizmy są specyficzne dla danej platformy
- Przy dużych aplikacjach przestaje się to opłacać
- Bardzo trudno jest używać ich efektywnie aby zoptymalizować koszty
- Musimy dostosowywać się pod dostawcę usługi
- Istnieje ryzyko zamknięcia usługi
Kiedy rozważać stosowanie BaaS?
Wszędzie tam gdzie jest potrzeba szybkiego uzyskania efektu aby wykonać prototyp. W szczególności w startupach, gdzie liczy się jak najlepszy efekt jak najmniejszym kosztem. Dzięki takiemu rozwiązaniu, gdy projektowana aplikacja zmieni się kilkanaście razy będzie możliwość jej przebudowy w prosty sposób. Podczas gdy się rozrośnie może zostać przeniesiona (lub nie) na klasyczną bazę danych.
Podsumowanie
Sposobów na obsługę bazy danych jest bardzo wiele. Nie ma jednego idealnego rozwiązania i wszystkie będą istnieć obok siebie. Ważne jest aby używać ich świadomie dostosowując je do naszego problemu. Zanim prace zostaną rozpoczęte powinna zostać poświęcona chwila na analizę oraz wybranie odpowiedniego na ten moment i stan wiedzy rozwiązania. Projektant powinien zdawać sobie sprawę z zalet oraz wad krótko oraz długoterminowych przy wyborze każdego ze sposobów.
Podczas podejmowania decyzji powinny zostać określone kryteria które są istotne oraz w jaki sposób będziemy mierzyć poprawność danego rozwiązania. Dla jednego przypadku może to być wydajność, dla drugiego łatwość utrzymania, a dla kolejnego skalowalność. Ważne aby umieć określić co jest dla nas ważne. Należy unikać przedwczesnej optymalizacji oraz bezmyślnego kopiowania przykładów z książek i tutoriali. Jeżeli to możliwe można porównać kilka sposób i wybrać optymalny dla danego systemu.
W znaczącej większości przypadków użycie ORM będzie lepszym i prostrzym rozwiązaniem. Jeżeli mielibyśmy go nie użyć należy odpowiedzieć sobie na pytanie dlaczego zastanawiamy się czy go nie użyć?
Ciekawy przykład z wydajnością ORM:https://github.com/dotnet/efcore/issues/18299
Dziękuję Grzegorzowi Elerykowi za pomoc w wykonaniu skalującej się tabelki.
https://github.com/GrzegorzEleryk